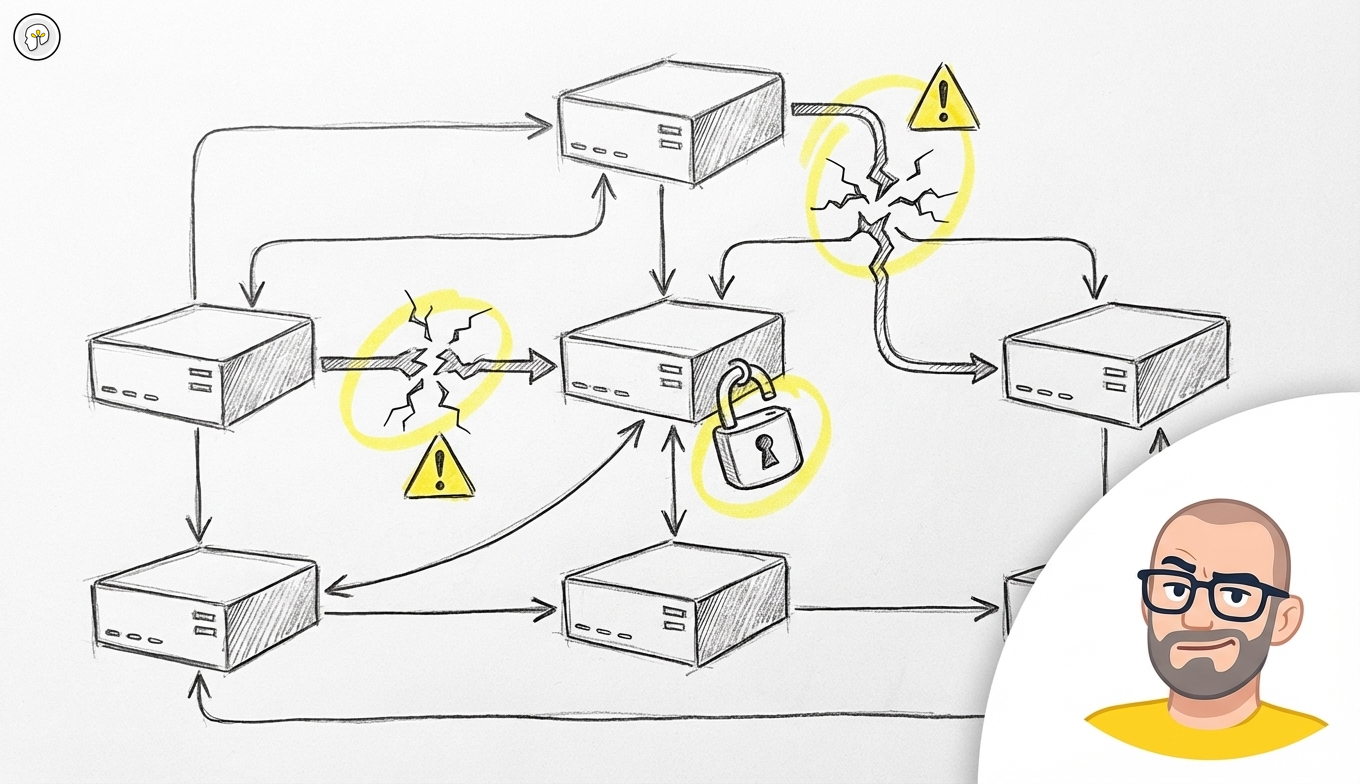
AI-säkerhetsparadoxen: det ingen varnar dig för med flerkomponentarkitekturer
Det här håller mig vaken om nätterna
"Alla pratar om AI-möjligheter. Nästan ingen pratar om säkerhetskonsekvenserna."
Jag har sett organisation efter organisation rusa ut för att driftsätta AI — koppla ihop tjänster, skicka data hit och dit — och sedan bli chockade, CHOCKADE, när säkerhetsproblemen dyker upp.
Här är den obekväma sanningen: De mest effektiva AI-implementationerna kräver de mest komplexa säkerhetsarkitekturerna. Och de flesta organisationer är inte ens i närheten av att vara redo för det.
Paradoxen är verklig: att bygga robusta AI-system kräver att man distribuerar förtroende över flera leverantörer och plattformar. Varje koppling är ett potentiellt säkerhetshål. Varje leverantör är en potentiell risk.
"En enskild modell räcker sällan. Det ger bättre effekt att koppla samman olika AI-lösningar för text, siffror och realtidsdata."
Denna arkitekturella verklighet skapar säkerhetsutmaningar som går långt bortom traditionellt skydd av mjukvarusystem. Organisationer måste nu hantera datasäkerhet över flera AI-tjänster — var och en med olika integritetspolicyer, lagringsplatser och efterlevnadskrav.
Vad AI-säkerhet inte kan garantera
Innan vi går vidare — låt mig vara tydlig med vad ingen arkitektur i världen kan lösa:
- AI kan inte hålla hemligheter — Om du skickar känslig data till en AI-tjänst är den skickad. Punkt.
- Leverantörer kan inte "avträna" — Data som redan använts för träning kan inte tas bort från modeller
- Efterlevnad kan inte automatiseras — GDPR, AI Act och sektorsregleringar kräver mänskligt omdöme
- Zero trust är fortfarande förtroende — Varje arkitektur förutsätter NÅGON nivå av förtroende någonstans
- Säkerhet kostar pengar — Det finns ingen gratislunch. Säker AI kostar mer.
"Säkerhet är inte en produkt. Det är en process — och den tar aldrig slut."
Nödvändigheten av flerkomponentsystem
Moderna AI-system kan inte leverera produktionskvalitet med en enda modell — olika AI-teknologier är bra på olika saker. Språkmodeller hanterar textförståelse och textgenerering effektivt men kämpar med numerisk analys och realtidsdatabehandling. Specialiserade analysmodeller utmärker sig på statistisk bearbetning men kan inte generera läsbara förklaringar. Realtidsmodeller ger aktuell information men saknar djup resonemangsförmåga.
"Skillnaden mellan språkmodeller, generiskt innehåll och dataanalys" speglar den grundläggande verkligheten att "en språkmodell i grunden är tränad för att tolka och producera språk — det vill säga text, konversationer och sammanhang."
Den här specialiseringen tvingar organisationer att bygga system som kombinerar flera AI-tjänster, där varje tjänst för med sig sina egna säkerhetshänsyn. Ett typiskt AI-system i produktion kan använda en tjänst för textbehandling, en annan för numerisk analys och en tredje för realtidsuppdateringar av data. Varje tjänst lagrar och bearbetar potentiellt känslig affärsdata på olika platser under olika säkerhetsramverk.
Den geopolitiska säkerhetsverkligheten
AI-säkerhetsbeslut har blivit geopolitiska frågor som påverkar affärsverksamheten på sätt som traditionell mjukvarusäkerhet aldrig gjorde. Organisationer utvärderar nu AI-leverantörer inte bara utifrån teknisk kapacitet utan också utifrån nationellt ursprung och datasuveränitetskonsekvenser.
"När asiatiska, och särskilt kinesiska, aktörer kommer på tal uppstår ofta en större tveksamhet, trots att privacy- och säkerhetsfrågorna i själva verket borde bedömas utifrån faktiska avtal och teknisk implementering, snarare än enbart ägarnas nationalitet."
Den här geopolitiska dimensionen skapar operativa komplexiteter för multinationella organisationer. Olika regioner har olika restriktioner kring användning av AI-leverantörer. Europeiska organisationer möter GDPR-efterlevnadsutmaningar när de använder AI-tjänster som lagrar data utanför EU. Amerikanska organisationer måste navigera restriktioner mot vissa utländska AI-leverantörer. Asiatiska organisationer kan möta begränsningar för västliga AI-tjänster.
Säkerhetsutvärderingen blir mer komplex eftersom organisationer måste bedöma inte bara tekniska säkerhetsåtgärder utan också politisk stabilitet, regelefterlevnad i flera jurisdiktioner och potentiella framtida restriktioner på leverantörsrelationer.
Den europeiska efterlevnadsutmaningen
Europeiska organisationer möter särskilt komplexa AI-säkerhetsutmaningar på grund av strikta dataskyddskrav som inte utformades med AI-system i åtanke.
"Juridiska risker med att använda AI-plattformar som lagrar data utanför EU."
GDPR-efterlevnad blir exponentiellt mer komplex med flerkomponent-AI-arkitekturer. Varje AI-tjänst bearbetar potentiellt personuppgifter, vilket kräver separata personuppgiftsbiträdesavtal, konsekvensbedömningar av integritetsskydd och löpande efterlevnadsövervakning. Organisationer måste spåra hur data flödar mellan AI-komponenter, var den lagras i varje steg och hur länge den sparas av varje tjänst.
Efterlevnadsutmaningen förvärras av att AI-tjänster ofta använder data för modellförbättring, vilket kan strida mot GDPR:s ändamålsbegränsningsprincip. Organisationer måste förhandla fram specifika klausuler med varje AI-leverantör för att förhindra obehörig dataanvändning — samtidigt som de behåller den funktionalitet som gör flerkomponent-AI-system effektiva.
Datasuveränitetens imperativ
I takt med att AI-system blir alltmer affärskritiska övergår datasuveränitet från att vara en efterlevnadsfråga till att bli ett strategiskt intresse.
"Var data hamnar och hur den lagras är minst lika viktigt som modellens prestanda."
Organisationer måste balansera AI-kapacitet mot kontroll över sin data. Det innebär att utvärdera inte bara var data lagras utan hur den bearbetas, vem som har tillgång till den och vad som händer med den efter att bearbetningen är klar. Flerkomponent-AI-arkitekturer komplicerar den här utvärderingen eftersom data kan flöda genom flera tjänster i olika jurisdiktioner.
Suveränitetsimperativet kräver att organisationer utvecklar dataklassificeringssystem som avgör vilka typer av information som kan bearbetas av vilka AI-tjänster. Högt känslig data kanske bara kan använda AI-tjänster on-premises eller i privat moln, medan mindre känslig data kan använda publika AI-API:er för bättre prestanda och kostnadseffektivitet.
Säkerhetsutvärderingens utveckling
Traditionella mjukvarusäkerhetsbedömningar fokuserar på kodgranskning, penetrationstestning och infrastruktursäkerhet. AI-säkerhet kräver ytterligare utvärderingskriterier som många organisationer inte är rustade att hantera.
"Granska leverantörers policy och ägarstruktur."
AI-säkerhetsbedömning måste inkludera utvärdering av leverantörers policyer för dataanvändning och åtaganden om att inte använda kunddata för modellträning. Det kräver förståelse för hur AI-leverantörer separerar kunddata från träningsdata och vilka tekniska åtgärder som förhindrar obehörig åtkomst.
Organisationer måste också bedöma leverantörers stabilitet och livslängd, eftersom beroenden av AI-tjänster är svårare att ersätta än traditionella mjukvaruberoenden. Att byta AI-leverantör kräver ofta att användare utbildas på nytt, att promptar och arbetsflöden uppdateras och att integrationer potentiellt byggs om. Det här inlåsningseffekten gör bedömning av leverantörssäkerhet och tillförlitlighet viktigare än för traditionella mjukvaruinköp.
Arkitekturens säkerhetsramverk
Framgångsrik AI-säkerhet kräver arkitekturella angreppssätt som förutsätter flera förtroendegränser snarare än att förlita sig på perimetersäkerhetsmodeller.
"Säkerställ dataflöden mellan komponenter."
Ramverket måste inkludera regler för dataklassificering och routing som avgör vilka typer av information som kan bearbetas av vilka AI-tjänster. Det kräver teknisk implementering av datafiltrering, kryptering vid överföring mellan AI-tjänster, övervakning och loggning av alla AI-tjänstinteraktioner samt automatiserad efterlevnadskontroll av datahanteringspolicyer.
Arkitekturen måste också inkludera reservmekanismer som upprätthåller säkerheten när AI-tjänster fallerar eller blir otillgängliga. Det kan innebära lokal bearbetningskapacitet för känsliga operationer eller alternativa AI-tjänster som uppfyller högre säkerhetsstandarder, även om de erbjuder lägre prestanda.
Avvägningen mellan kostnad och säkerhet
Flerkomponent-AI-arkitekturer tvingar organisationer att göra explicita avvägningar mellan kapacitet, kostnad och säkerhet — avvägningar som inte är uppenbara utifrån enkla AI-demonstrationer.
Högre säkerhet innebär typiskt högre kostnader genom privata molndriftsättningar, dedikerade instanser eller AI-lösningar on-premises. Det kan också innebära lägre prestanda genom begränsade AI-tjänster som uppfyller säkerhetskraven men erbjuder mindre kapacitet än publika alternativ.
Organisationer måste utveckla ramverk för att göra dessa avvägningar systematiskt, snarare än att per automatik välja antingen maximal säkerhet eller maximal kapacitet. Det kräver förståelse för affärsvärdet av olika typer av AI-kapacitet och de faktiska riskerna med olika säkerhetsangreppssätt.
Integrationens säkerhetsmönster
Framgångsrik AI-säkerhetsimplementation följer specifika mönster som organisationer kan anpassa efter sina specifika krav och risktolerans.
Zero trust-mönstret behandlar varje AI-tjänst som potentiellt komprometterad och implementerar validering vid varje integrationspunkt. Det inkluderar kryptering av data mellan AI-tjänster, validering av AI-utdata innan de används i affärslogik, övervakning av alla AI-tjänstinteraktioner för avvikelser och implementering av automatiserade incidentresponser för säkerhetsöverträdelser.
Det skiktade säkerhetsmönstret implementerar olika säkerhetsnivåer för olika typer av data och operationer. Högt känsliga operationer använder AI-tjänster on-premises eller privata AI-tjänster med maximala säkerhetskontroller. Måttligt känsliga operationer använder publika AI-tjänster med förstärkt övervakning och datahanteringsavtal. Låg-känsliga operationer använder standardmässiga publika AI-tjänster för maximal prestanda och kostnadseffektivitet.
Övervakningens och efterlevnadens verklighet
AI-säkerhet kräver kontinuerlig övervakning som går bortom traditionella säkerhetsmätvärden och inkluderar AI-specifika indikatorer på kompromettering eller efterlevnadsöverträdelser.
Det inkluderar övervakning av dataintrång via AI-tjänstinteraktioner, spårning av efterlevnad med datahanteringsavtal hos flera leverantörer, detektering av ovanliga mönster i AI-tjänstanvändning som kan indikera säkerhetsincidenter samt mätning av AI-tjänsters tillförlitlighet och tillgänglighet för affärskontinuitetsplanering.
Övervakningsramverket måste också inkludera regelbunden revision av AI-leverantörers efterlevnad av säkerhetsavtal och bedömning av förändrade geopolitiska restriktioner som kan påverka AI-tjänsters tillgänglighet eller efterlevnadskrav.
Slutsats: säkerhet som arkitektonisk grund
AI-säkerhet kan inte vara en eftertanke i flerkomponentarkitekturer — det måste vara en grundläggande designprincip som påverkar varje arkitektoniskt beslut.
"Många av framtidens vinnare är de som lär sig kombinera olika AI- och ML-komponenter för att bygga flexibla och kraftfulla arbetsflöden."
Vinnarna blir de organisationer som bemästrar komplexiteten i säkra flerkomponent-AI-arkitekturer — inte de som undviker AI av säkerhetsskäl, och inte de som ignorerar säkerheten för AI-kapacitetens skull.
Den viktigaste insikten är att AI-säkerhet kräver samma systematiska tänkande och arkitektoniska disciplin som organisationer tillämpar på andra kritiska affärssystem. Säkerhet blir mer komplex med AI — men det är hanterbart med rätt ramverk och systematisk implementering.
Jämförelsematris för leverantörssäkerhet
När organisationer utvärderar AI-leverantörer för flerkomponentarkitekturer måste de bedöma flera dimensioner utöver teknisk kapacitet:
| Leverantör | Policy för träningsdata | EU-hosting | GDPR-klart DPA | SOC 2 | Ägarskap |
|---|---|---|---|---|---|
| OpenAI | Opt-out (konsument), Nej (enterprise/API) | Via Azure endast | Ja (enterprise) | Ja | USA (Microsoft-andel) |
| Anthropic (Claude) | Tränar aldrig på användardata | Nej (USA endast) | Ja | Ja | USA |
| Google (Gemini) | Opt-out (konsument), Nej (Workspace/Vertex) | Ja (Vertex AI) | Ja | Ja | USA |
| Microsoft (Azure OpenAI) | Nej | Ja | Ja | Ja | USA |
| Mistral | Nej (API) | Ja (EU-nativt) | Ja | Pågående | Frankrike/EU |
Leverantörsval per användningsfall
Maximal EU-efterlevnad: 1. Microsoft Azure OpenAI (EU-region) 2. Google Vertex AI (EU-region) 3. Mistral (EU-nativt)
Bästa integritetspolicyer: 1. Anthropic Claude (tränar aldrig) 2. Azure OpenAI (enterprise-kontroller) 3. Google Vertex AI (enterprise-kontroller)
Rekommendationer för svenska organisationer: - Börja med Microsoft om du redan använder M365/Azure - Överväg Google om du använder Workspace - Använd Claude för högkänslig analys (acceptera US-hosting) - Utvärdera Mistral för EU-suveräna krav
Svenska och nordiska specifika överväganden
Regulatorisk kontext
Svenska organisationer möter en specifik regulatorisk kontext:
Offentlighetsprincipen: - Offentliga organisationer måste överväga om AI-interaktioner blir allmänna handlingar - Dokumentera vilken data som skickas till AI-tjänster - Implementera loggning för transparenskrav
Arbetsmiljölagen: - AI-implementation påverkar arbetsförhållanden - Involvera fackliga representanter/skyddsombud i AI-driftsättningsbeslut - Dokumentera AI:s roll i beslutsprocesser
Branschspecifika krav: - Bank (Finansinspektionen): Ytterligare krav för AI i finansiella beslut - Sjukvård (IVO): Patientdata kan inte använda standardmässiga AI-tjänster - Försvar (FMV): Begränsad lista på godkända AI-leverantörer
Alternativ för dataplacering för svenska organisationer
| Kravnivå | Rekommenderat angreppssätt | Avvägningar |
|---|---|---|
| Standardaffärsdata | Azure OpenAI (Sverige/EU) eller Google Vertex (EU) | Full kapacitet, standardefterlevnad |
| Personuppgifter (GDPR) | Azure OpenAI med DPA, EU-region endast | Viss latens, högre kostnad |
| Känsliga kategorier (Art. 9) | On-premises-lösningar eller ingen AI | Betydande kapacitetsbortfall |
| Sekretessbelagd information | Enbart svenska suveräna lösningar | Mycket begränsade AI-alternativ |
Praktiska rekommendationer för svenska organisationer
- Klassificera data först — Innan AI-adoption, bestäm vilka datatyper som kan processas var
- Etablera DPA med varje leverantör — Standardvillkor räcker inte för GDPR
- Dokumentera dataflöden — Var går datan? Vem har access? Hur länge sparas den?
- Involvera juridik tidigt — AI-säkerhet är en juridisk fråga, inte bara teknisk
- Planera för förändring — Regulatoriska krav på AI kommer skärpas (AI Act 2025+)
Implementationschecklista
Fas 1: Bedömning
- [ ] Klassificera datatyper efter känslighet
- [ ] Kartlägg befintlig och planerad AI-tjänstanvändning
- [ ] Identifiera regulatoriska krav (bransch, geografi)
- [ ] Dokumentera befintliga dataflöden och lagringsplatser
Fas 2: Arkitekturdesign
- [ ] Definiera säkerhetsnivåer för olika datatyper
- [ ] Välj leverantörer som uppfyller varje nivås krav
- [ ] Designa datarouting mellan komponenter
- [ ] Planera reservmekanismer för säkerhetsfel
Fas 3: Implementation
- [ ] Förhandla DPA med alla AI-leverantörer
- [ ] Implementera tekniska kontroller (kryptering, åtkomstkontroll)
- [ ] Driftsätt övervakning och loggning
- [ ] Utbilda personal i säkerhetsprocedurer
Fas 4: Drift
- [ ] Regelbunden revision av leverantörernas efterlevnad
- [ ] Kontinuerlig övervakning av avvikelser
- [ ] Incidentresponsprocedurer
- [ ] Periodisk arkitekturgranskning
Ditt ansvar
"Du är ansvarig för varje dataläcka, oavsett vad leverantören lovade."
Låt mig vara direkt: leverantörer kommer inte att skydda dig. Användarvillkor är utformade för att begränsa DERAS ansvar — inte för att skydda DIG.
Vad du måste acceptera: - Säkerhet är ditt problem, inte leverantörens - "Enterprise-grade" är marknadsföring, inte en garanti - Att bocka av efterlevnadskrav innebär inte faktisk säkerhet - Det billigaste alternativet är aldrig det säkraste
Vad du måste göra: - Klassificera din data INNAN du väljer AI-verktyg - Få juridiskt godkännande för varje leverantörsrelation - Övervaka faktiska dataflöden, inte bara policyer - Planera för intrång — inte bara för att förhindra dem - Budgetera för säkerhet — det kostar 20–50 % mer än osäkra alternativ
Slutsats: säkerhet är inte valfritt
Organisationer som ignorerar AI-säkerhet har ingen rätt att klaga när intrång inträffar. Organisationer som är besatta av säkerhet utan att driftsätta AI går miste om fördelarna. Vinnarna hittar balansen.
"Många av framtidens vinnare är de som lär sig kombinera olika AI- och ML-komponenter för att bygga flexibla och kraftfulla arbetsflöden."
Men de vinnarna är de som gjorde säkerhetsarbetet FÖRST — inte som en eftertanke.
Den viktigaste insikten: AI-säkerhet kräver MER systematiskt tänkande än traditionell mjukvarusäkerhet — inte mindre. Om du inte är beredd på det är du inte redo för AI i produktion.
AI är ett verktyg. Säkerhet är ditt ansvar. Verktyg, inte magi.
Se även: AI Training Data Policies för detaljerad jämförelse av leverantörers datahantering.
Baserat på 30 års produktionsutveckling och att ha bevittnat säkerhetshavererna i verkliga organisationer Publicerad: december 2025